|
I am a Research Scientist at Meta Superintelligence Labs. My work focuses on building unified multimodal foundation models that bridge understanding, generation, and editing across text, image, video, and audio. Before that I worked at Adobe Firefly, Amazon AGI Foundations and AWS AI Labs where I was part of the team that launched Titan Image Generator (Nova Canvas). I received my PhD at University of Maryland, College Park in 2020, advised by Professor Rama Chellappa. I interned at Waymo, Adobe Research, Palo Alto Research Center, and Siemens Healthineers during my PhD. |

|
|
|
|
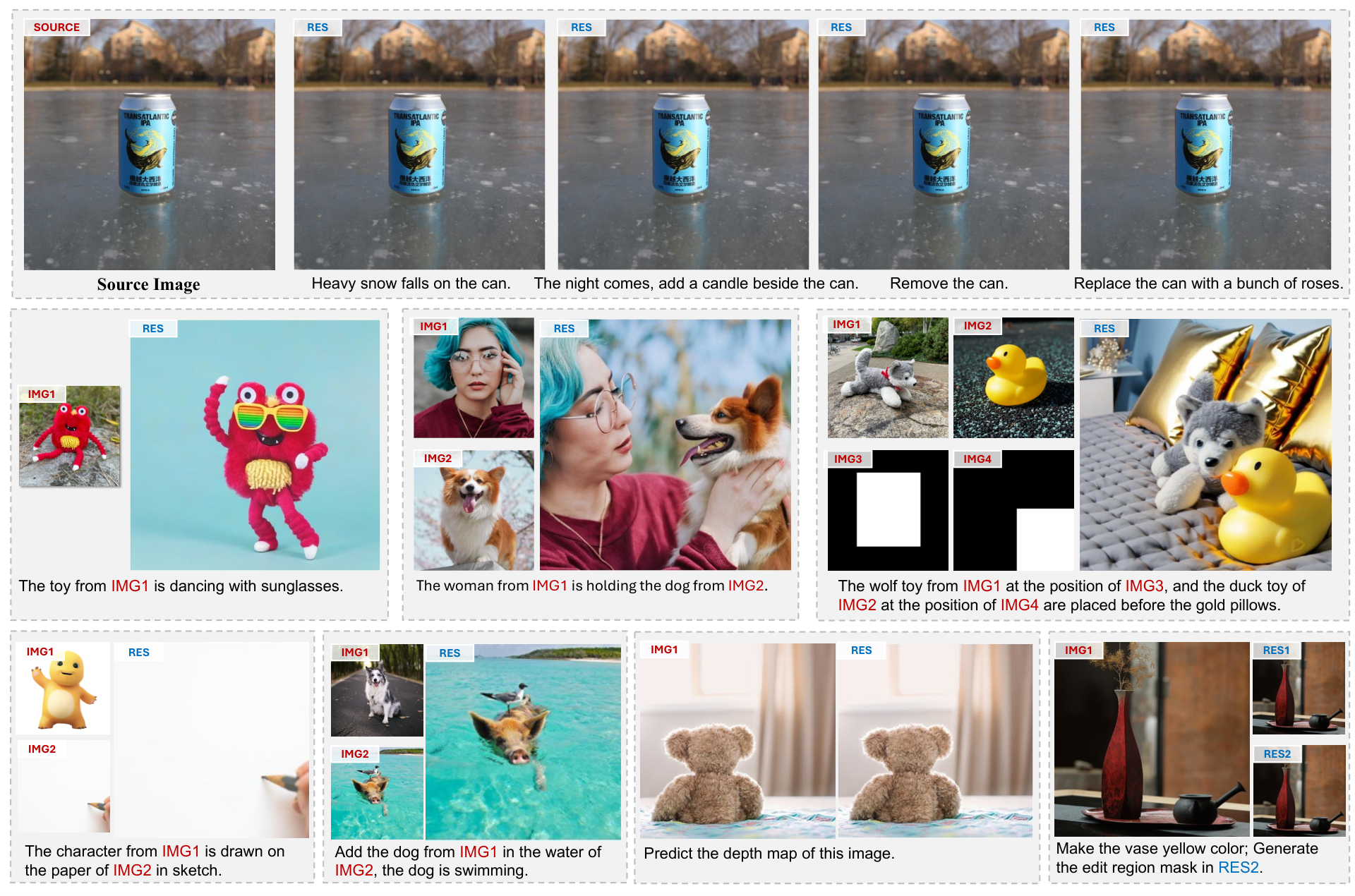
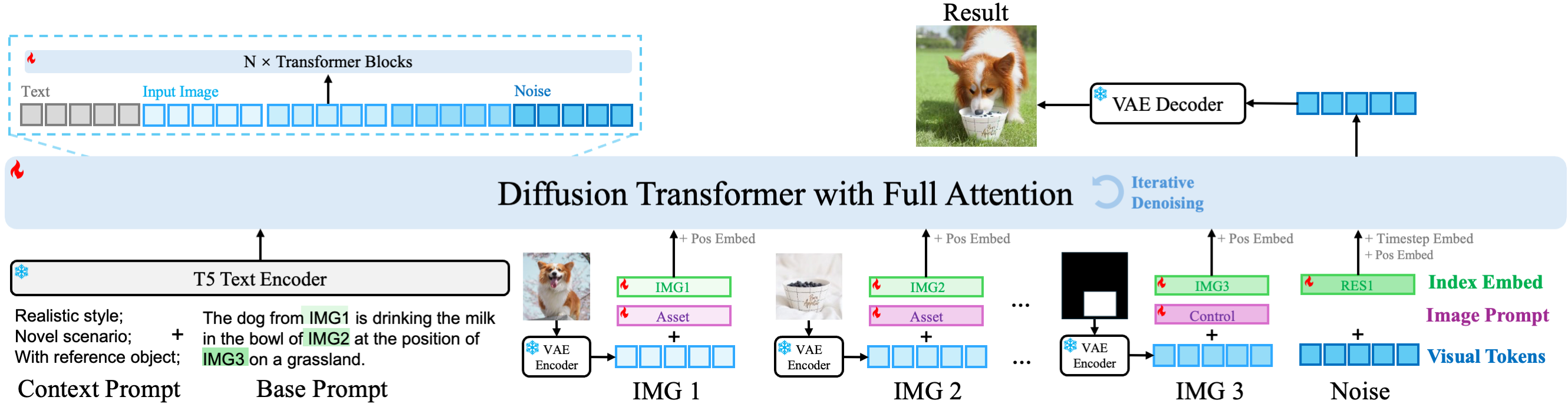
Xi Chen, Zhifei Zhang, He Zhang, Yuqian Zhou, Soo Ye Kim, Qing Liu, Yijun Li, Jianming Zhang, Nanxuan Zhao, Yilin Wang, Hui Ding, Zhe Lin, Hengshuang Zhao CVPR Highlight, 2025 Project Page / arXiv As a universal framework, UniReal supports a broad spectrum of image generation and editing tasks within a single model, accommodating diverse input-output configurations and generating highly realistic results, which effectively handle challenging scenarios, e.g., shadows, reflections, lighting effects, object pose changes, etc. |
|
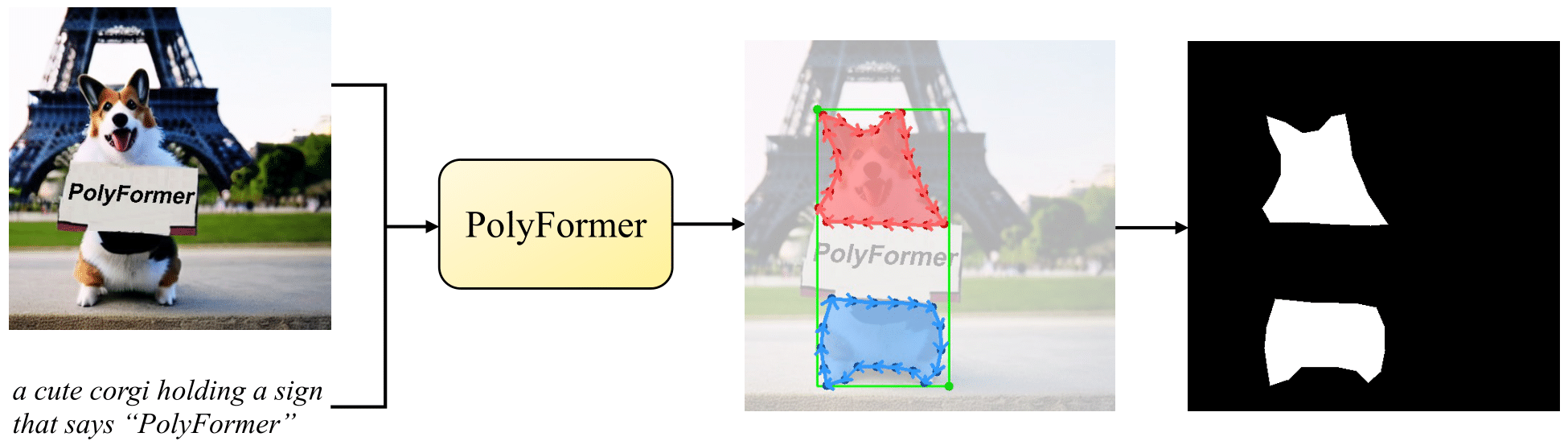
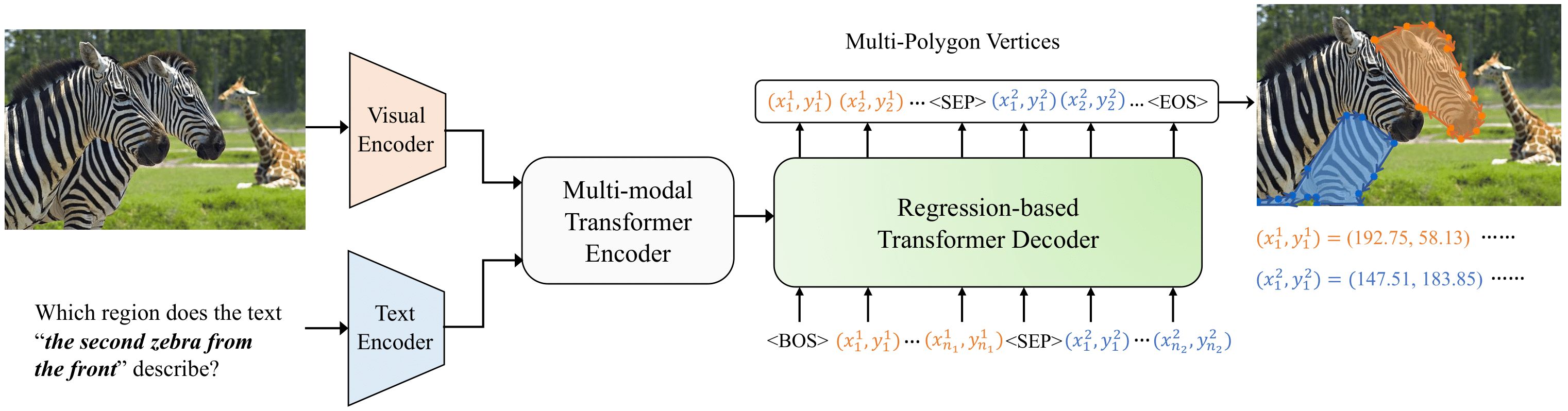
Jiang Liu*, Hui Ding*, Zhaowei Cai, Yuting Zhang, Ravi Kumar Satzoda, Vijay Mahadevan, R. Manmatha (*equal contribution) CVPR, 2023 Project Page / arXiv / code Instead of directly predicting the pixel-level segmentation masks, the problem of referring image segmentation is formulated as sequential polygon generation, and the predicted polygons can be later converted into segmentation masks. This is enabled by a new sequence-to-sequence framework, Polygon Transformer (PolyFormer), which takes a sequence of image patches and text query tokens as input, and outputs a sequence of polygon vertices autoregressively. |
|
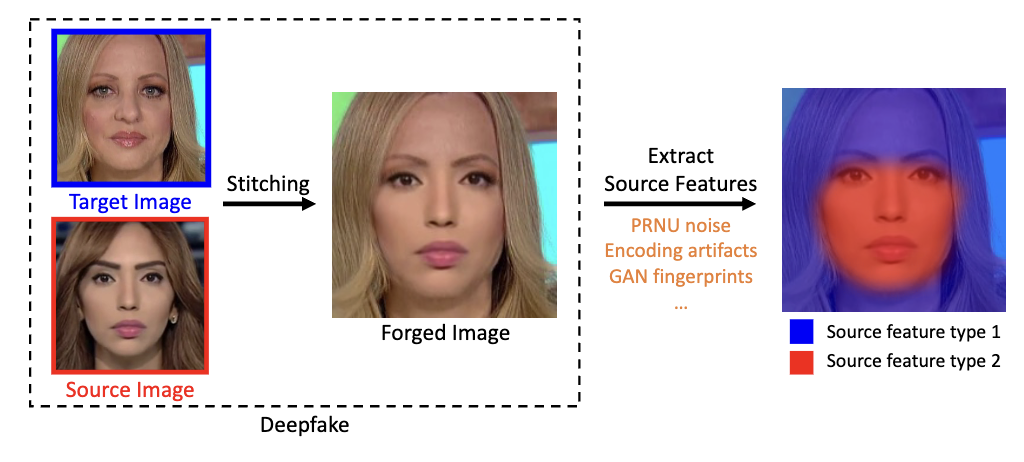
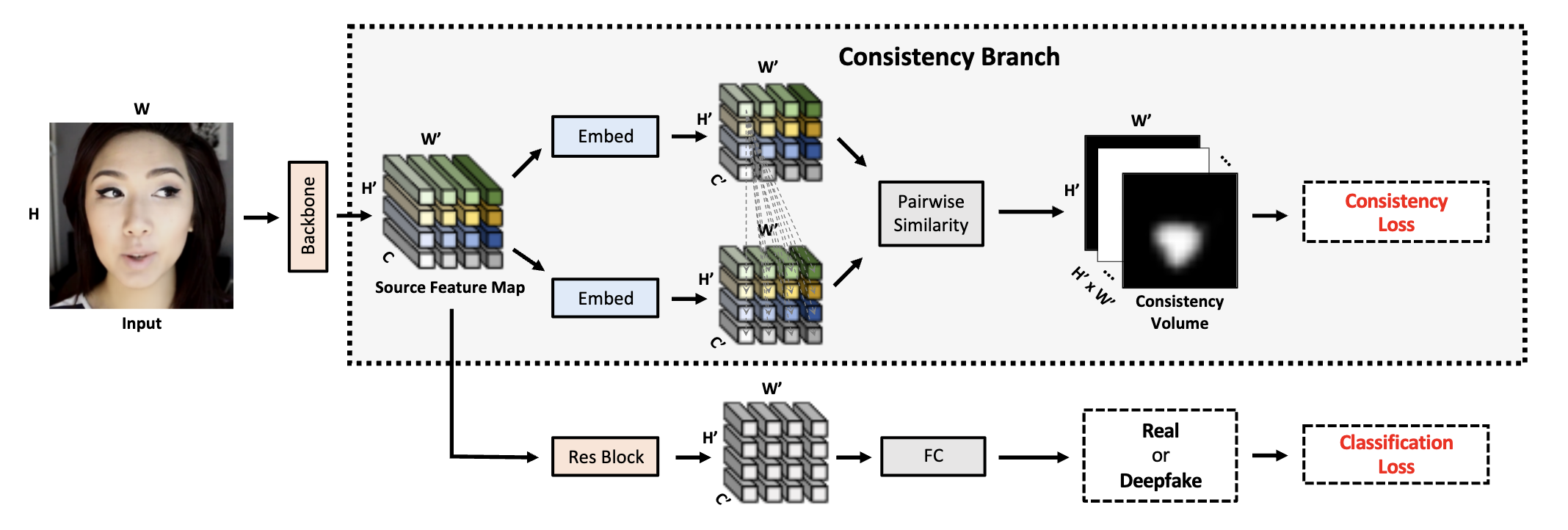
Tianchen Zhao, Xiang Xu, Mingze Xu, Hui Ding, Yuanjun Xiong, and Wei Xia ICCV Oral, 2021 arXiv We introduce a novel representation learning ap- proach, called pair-wise self-consistency learning (PCL), for training ConvNets to extract these source features and detect deepfake images. |
|
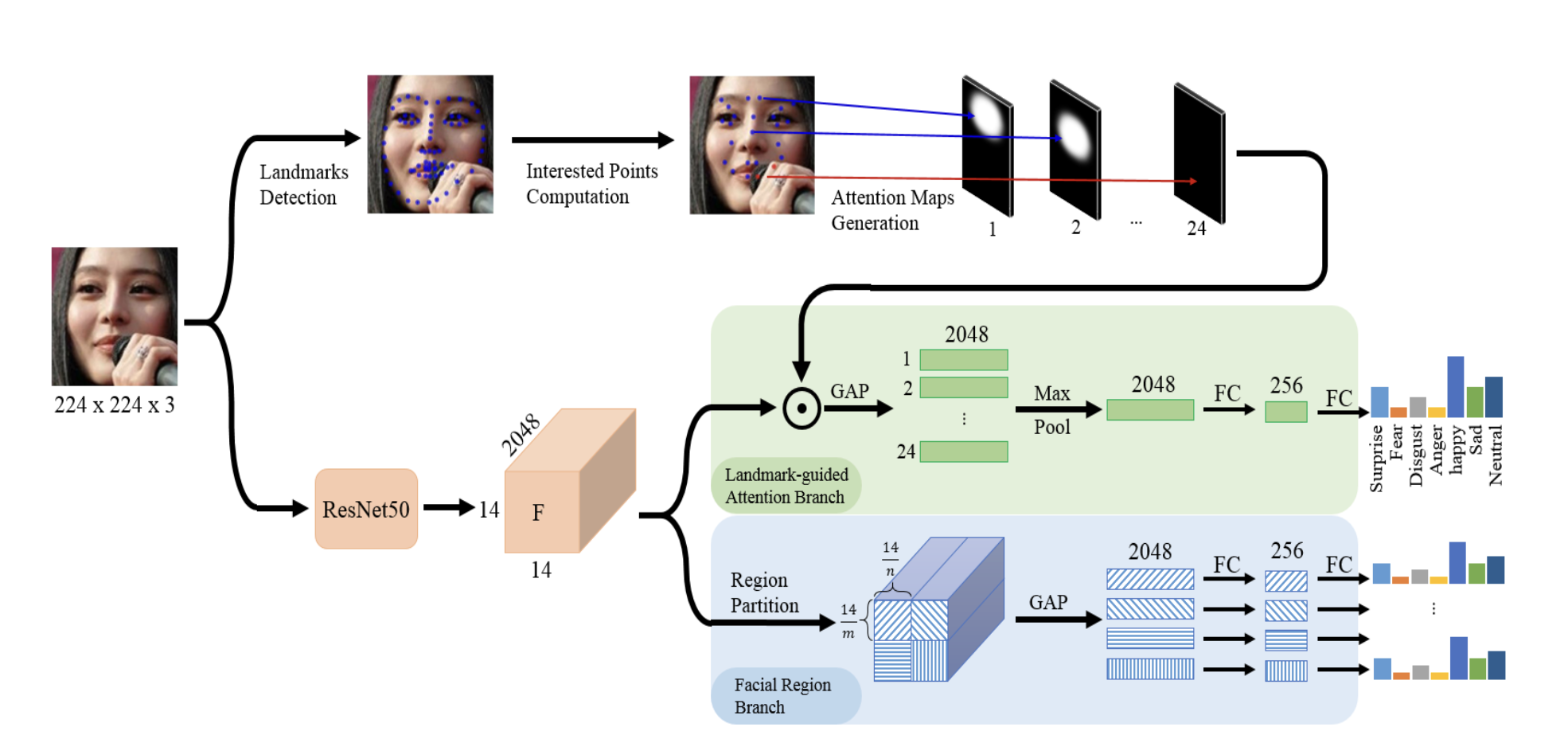
Hui Ding, Peng Zhou and Rama Chellappa International Joint Conference on Biometrics (IJCB) Oral, 2020 arXiv We propose a landmark-guided attention branch to find and discard corrupted features from occluded regions so that they are not used for recognition. To further improve robustness, we propose a facial region branch to partition the feature maps into non-overlapping facial blocks and task each block to predict the expression independently. |
|
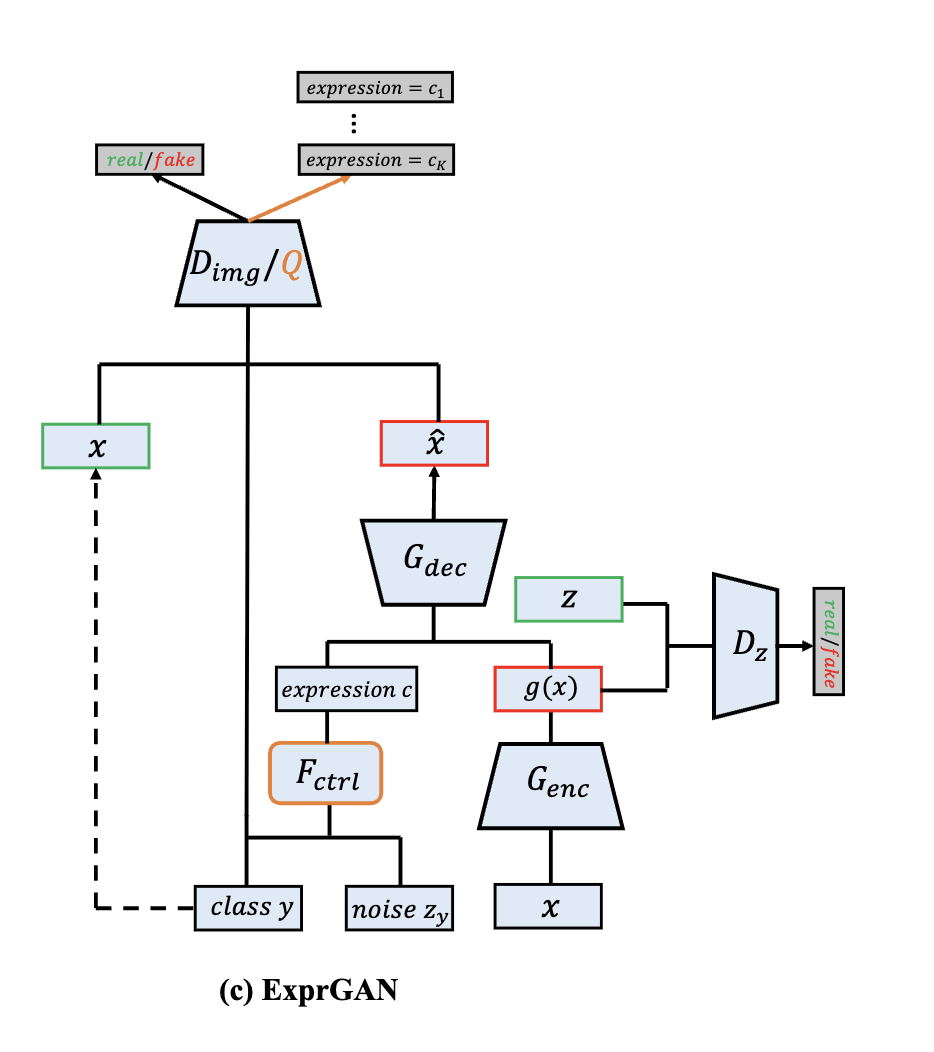
Hui Ding, Kumar Sricharan and Rama Chellappa AAAI Oral, 2018 arXiv / code We propose an Expression Generative Adversarial Network (ExprGAN) for photo-realistic facial expression editing with controllable expression intensity. An expression controller module is specially designed to learn an expressive and compact expression code in addition to the encoder-decoder network. This novel architecture enables the expression intensity to be continuously adjusted from low to high. |
|
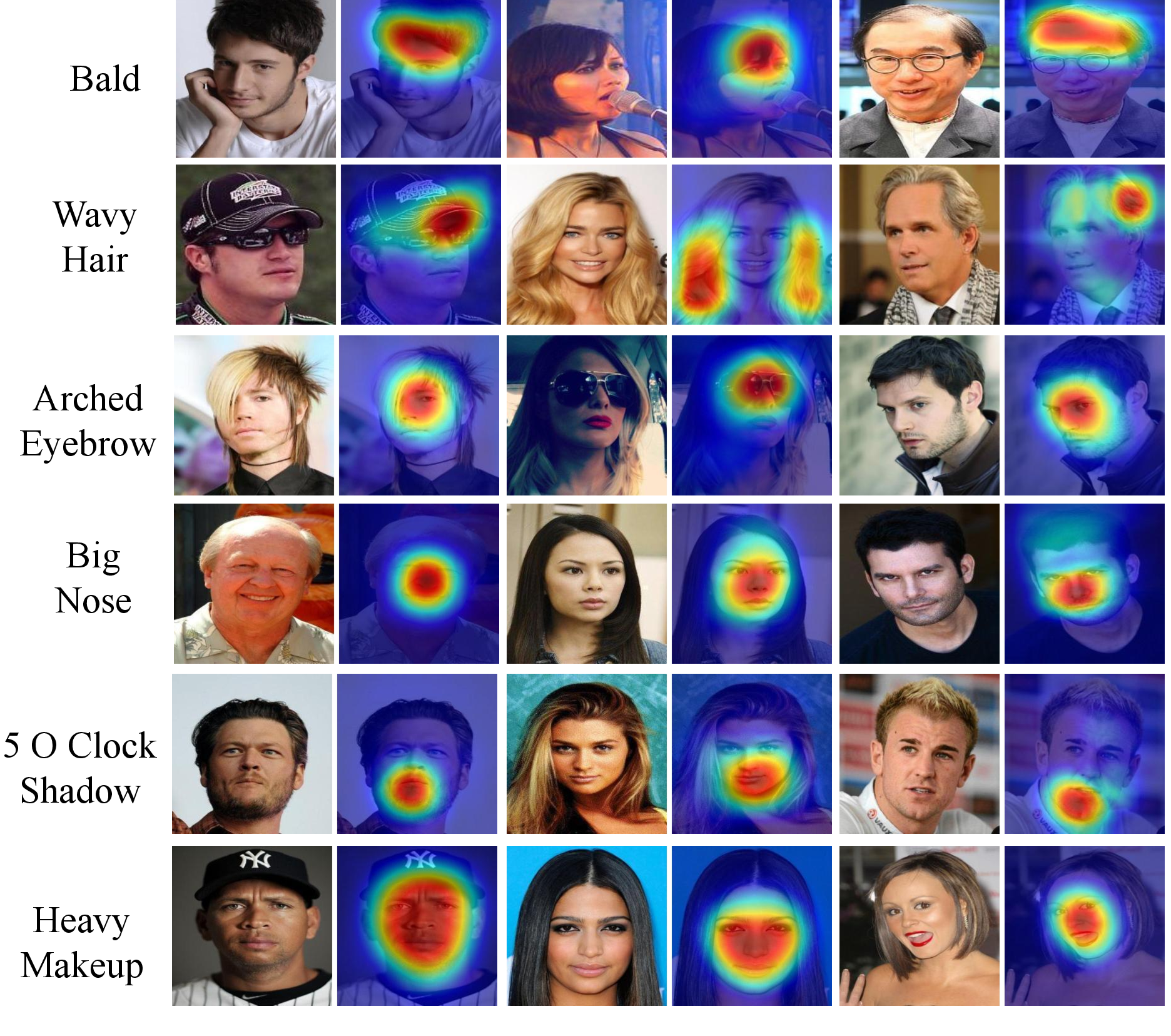
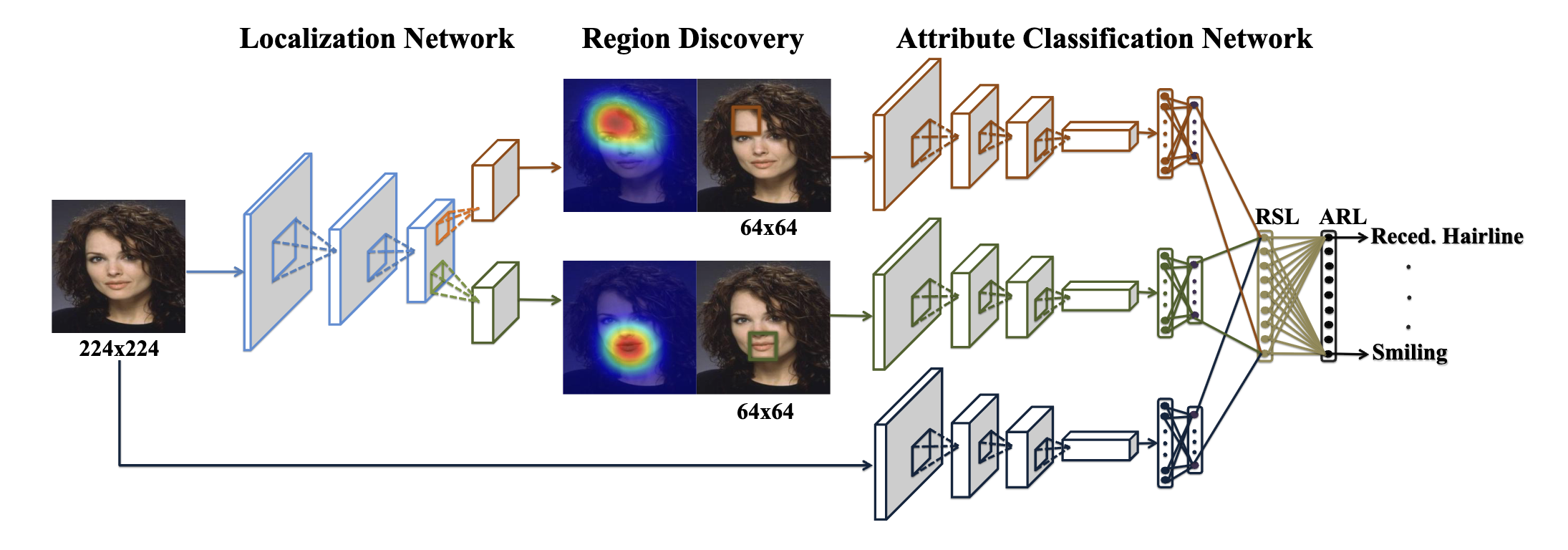
Hui Ding, Hao Zhou, Shaohua Kevin Zhou and Rama Chellappa AAAI Spotlight, 2018 arXiv We propose a cascade network that simultaneously learns to localize face regions specific to attributes and performs attribute classification without alignment. First, a weakly-supervised face region localization net- work is designed to automatically detect regions (or parts) specific to attributes. Then multiple part-based networks and a whole-image-based network are separately constructed and combined together by the region switch layer and attribute re- lation layer for final attribute classification. |
|
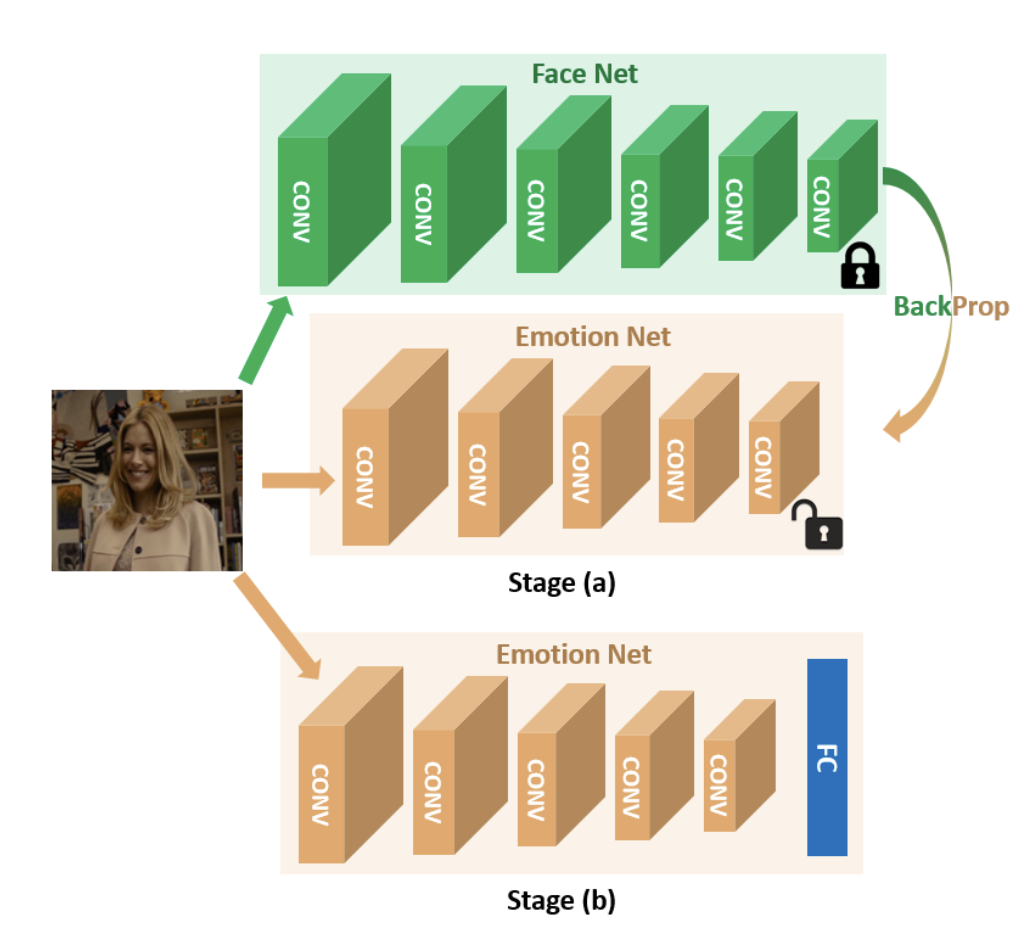
Hui Ding, Shaohua Kevin Zhou and Rama Chellappa IEEE International Conference on Automatic Face Gesture Recognition (FG), 2017 arXiv Relatively small data sets available for expression recognition research make the training of deep networks for expression recognition very challenging. We present FaceNet2ExpNet, a novel idea to train an expression recognition network based on static images. We first propose a new distribution function to model the high-level neurons of the expression network. Based on this, a two-stage training algorithm is carefully designed. |
|
|